Bimanual DexHands
Bi-DexHands: Towards Human-Level Bimanual Dexterous Manipulation with Reinforcement Learning
This project is maintained by PKU-MARL
Bi-DexHands: Towards Human-Level Bimanual Dexterous Manipulation with Reinforcement Learning

We propose a bimanual dexterous manipulation benchmark (Bi-DexHands) according to literature from cognitive science for comprehensive reinforcement learning research. Bi-DexHands are developed with the following key features:
- Isaac Efficiency: Bi-DexHands is built within Isaac Gym; it supports running thousands of environments simultaneously. On one NVIDIA RTX 3090 GPU, Bi-DexHands can reach 30,000+ mean FPS by running 2,048 environments in parallel.
- Comprehensive RL Benchmark: we provide the first bimanual manipulation task environment for common RL, MARL, Multi-task RL, Meta RL, and Offline RL practitioners, along with a comprehensive benchmark for SOTA continuous control model-free RL/MARL methods.
- Heterogeneous-agents Cooperation: Agents in Bi-DexHands (i.e., joints, fingers, hands,…) are genuinely heterogeneous; this is very different from common multi-agent environments such as SMAC where agents can simply share parameters to solve the task.
- Task Generalization: we introduce a variety of dexterous manipulation tasks (e.g., handover, lift up, throw, place, put…) as well as enormous target objects from the YCB and SAPIEN dataset (>2,000 objects); this allows meta-RL and multi-task RL algorithms to be tested on the task generalization front.
- Cognition: We provided the underlying relationship between our dexterous tasks and the motor skills of humans at different ages. This facilitates researchers on studying robot skill learning and development, in particular in comparison to humans.
Quick Demo

Concept Video

Introduction
Achieving human-level dexterity is an important open problem in robotics. However, tasks of dexterous hand manipulation, even at the baby level, are challenging to solve through reinforcement learning (RL). The difficulty lies in the high degrees of freedom and the required cooperation among heterogeneous agents (e.g., joints of fingers). In this study, we propose the Bimanual Dexterous Hands Benchmark (Bi-DexHands), a simulator that involves two dexterous hands with tens of bimanual manipulation tasks and thousands of target objects. Specifically, tasks in Bi-DexHands are designed to match different levels of human motor skills according to cognitive science literature. We built Bi-DexHands in the Issac Gym; this enables highly efficient RL training, reaching 30,000+ FPS by only one single NVIDIA RTX 3090.
We provide a comprehensive benchmark for popular RL algorithms under different settings; this includes Single-agent/Multi-agent RL, Offline RL, Multi-task RL, and Meta RL. Our results show that the PPO type of on-policy algorithms can master simple manipulation tasks that are equivalent up to 48-month human babies (e.g., catching a flying object, opening a bottle), while multi-agent RL can further help to master manipulations that require skilled bimanual cooperation (e.g., lifting a pot, stacking blocks). Despite the success on each single task, when it comes to acquiring multiple manipulation skills, existing RL algorithms fail to work in most of the multi-task and the few-shot learning settings, which calls for more substantial development from the RL community.
Our project is open sourced at https://github.com/PKU-MARL/DexterousHands.
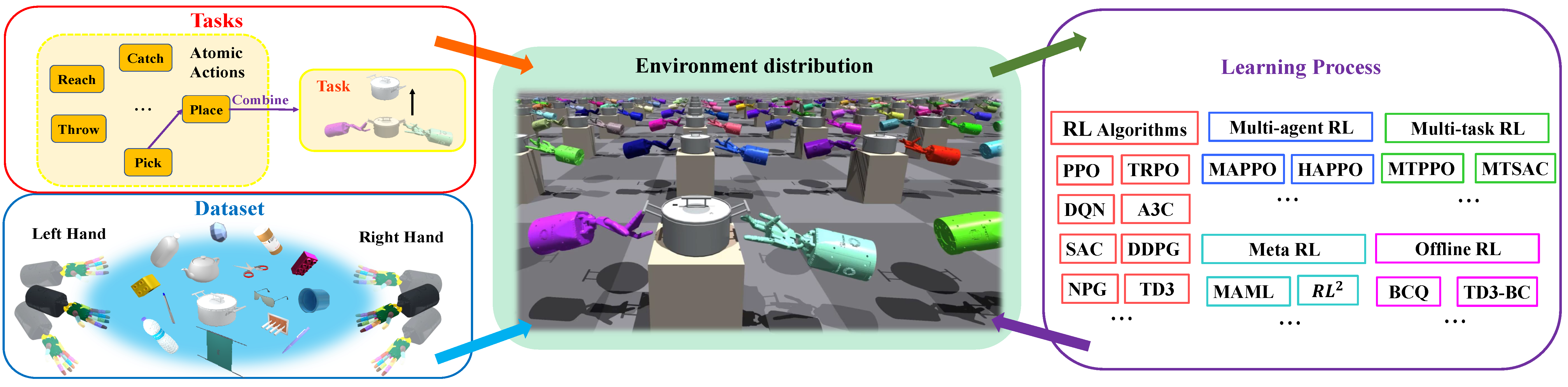
Framework
Framework of Bi-DexHands, a bechmark for learning bimanual dexterous manipulation.
Results
We conduct a full benchmark of the RL algorithms. All of our experiments are run with Intel i7-9700K CPU @ 3.60GHz and NVIDIA RTX 3090 GPU.
RL/MARL results
Currently, we only evaluate the performance of PPO, SAC, MAPPO, and HAPPO algorithms on these 20 tasks, and we implemented the rest of the RL/MARL algorithms in our Github repository. Learning curves for all 20 tasks is shown in below. The shaded region represents the standard deviation of the score over 10 trials. Curves are smoothed uniformly for visual clarity. All algorithms interact with environments in 100M steps and the number of parallel simulations is 2048.
Offline RL results
We evaluate behavior cloning (BC), BCQ, TD3+BC, and IQL on two tasks, Hand Over and Door Open Outward, and report normalized scores in below.
| Tasks | Datasets | Online PPO | BC | BCQ | TD3+BC | IQL |
|---|---|---|---|---|---|---|
| HandOver | random | 100.0 | 0.7 | 1.0 | 0.9 | 0.7 |
| replay | 100.0 | 17.5 | 61.6 | 70.1 | 43.1 | |
| medium | 100.0 | 61.6 | 66.1 | 65.8 | 57.4 | |
| medium-expert | 100.0 | 63.3 | 81.7 | 84.9 | 67.2 | |
| DoorOpenOutward | random | 100.0 | 2.1 | 23.8 | 34.9 | 3.8 |
| replay | 100.0 | 36.9 | 48.8 | 60.5 | 31.7 | |
| medium | 100.0 | 63.9 | 60.1 | 66.3 | 56.6 | |
| medium-expert | 100.0 | 69.0 | 73.7 | 71.9 | 53.8 |
Multi-task RL results
Multi-task reinforcement learning aims to train a single policy, which can achieve good results on different tasks. We evaluate the multi-task PPO algorithms on MT1, MT4, amd MT20. We also provided the results of random policy and using the PPO algorithm in individual task as the ground truth for comparison. The average reward for each training is shown in below.
| Method | MT1 | MT4 | MT20 |
|---|---|---|---|
| Ground Truth | 15.2 | 24,3 | 32.5 |
| Multi-task PPO | 9.4 | 5.4 | 8.9 |
| Random | 0.61 | 1.1 | -2.5 |
Meta RL results
Meta RL, also known as learning to learn, aims to gain the ability to train on tasks to extract the common features of these tasks, so as to quickly adapt to new and unseen tasks. We evaluate the ProMP algorithms on ML1, ML4, amd ML20. We also provided the results of random policy and using the PPO algorithm in individual task as the ground truth for comparison. The average reward for each training is shown in below.
| Method | ML1 | ML4 | ML20 | |||
|---|---|---|---|---|---|---|
| Train | Test | Train | Test | Train | Test | |
| Ground Truth | 15.0 | 15.8 | 28.0 | 13.1 | 33.7 | 26.1 |
| ProMP | 0.95 | 1.2 | 2.5 | 0.5 | 0.02 | 0.36 |
| Random | 0.59 | 0.68 | 1.5 | 0.24 | -2.9 | 0.27 |
Code
Please see our github repo for code and data of this project.
Citation
@misc{2206.08686,
Author = {Yuanpei Chen and Yaodong Yang and Tianhao Wu and Shengjie Wang and Xidong Feng and Jiechuang Jiang and Stephen Marcus McAleer and Hao Dong and Zongqing Lu and Song-Chun Zhu},
Title = {Towards Human-Level Bimanual Dexterous Manipulation with Reinforcement Learning},
Year = {2022},
Eprint = {arXiv:2206.08686},
}
Contact
Bi-DexHands is a project contributed by Yuanpei Chen, Yaodong Yang, Tianhao Wu, Shengjie Wang, Xidong Feng, Jiechuang Jiang, Hao Dong, Zongqing Lu, Song-chun Zhu at Peking University, please contact yaodong.yang@pku.edu.cn if you are interested to collaborate.